B+树索引
对于非主键的查找过程是如何?
索引
如果想要快速的找到数据在哪个页,我没必须为数据页也建立一个目录,建这个目录必须完成下面这些事:
- 下一个数据页中用户记录的主键值必须大于上一个页中用户记录的主键值.
下面展示数据页模型的简单示例: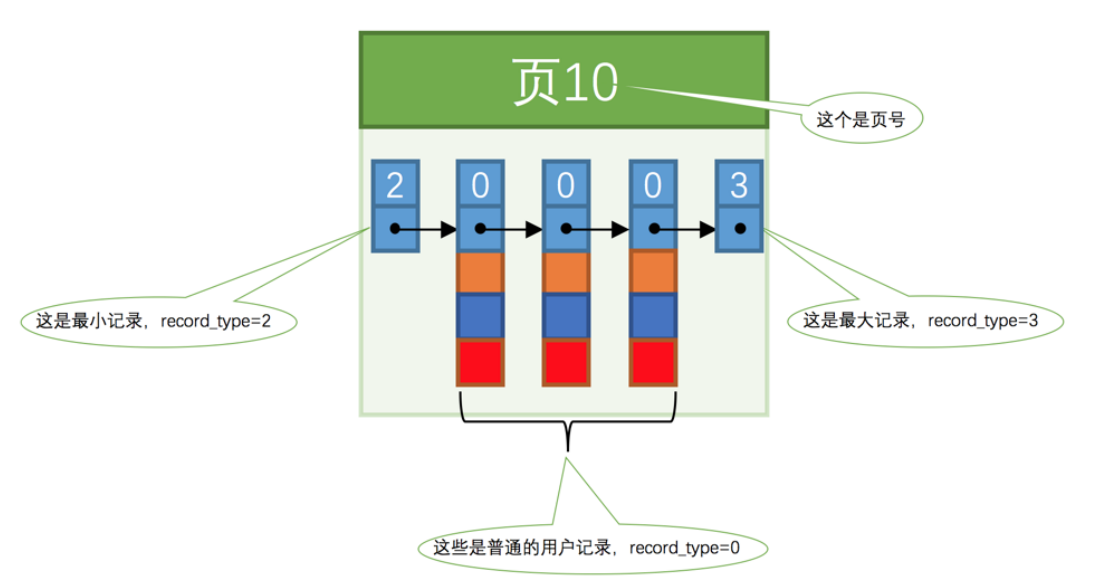
黄色代表主键,由于数据页不是连续的,在向表中插入许多数据后,可能是这样的效果: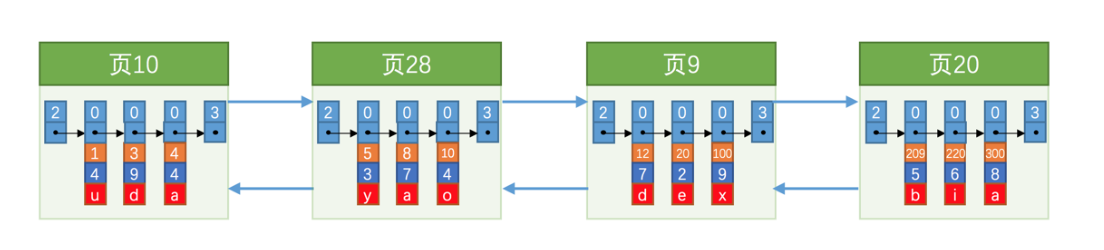
下面我们为这几个页做目录,每个目录项包含以下内容:
- 页的用户记录中最小的主键值,我们用key表示
- 页号,我们用page_no表示
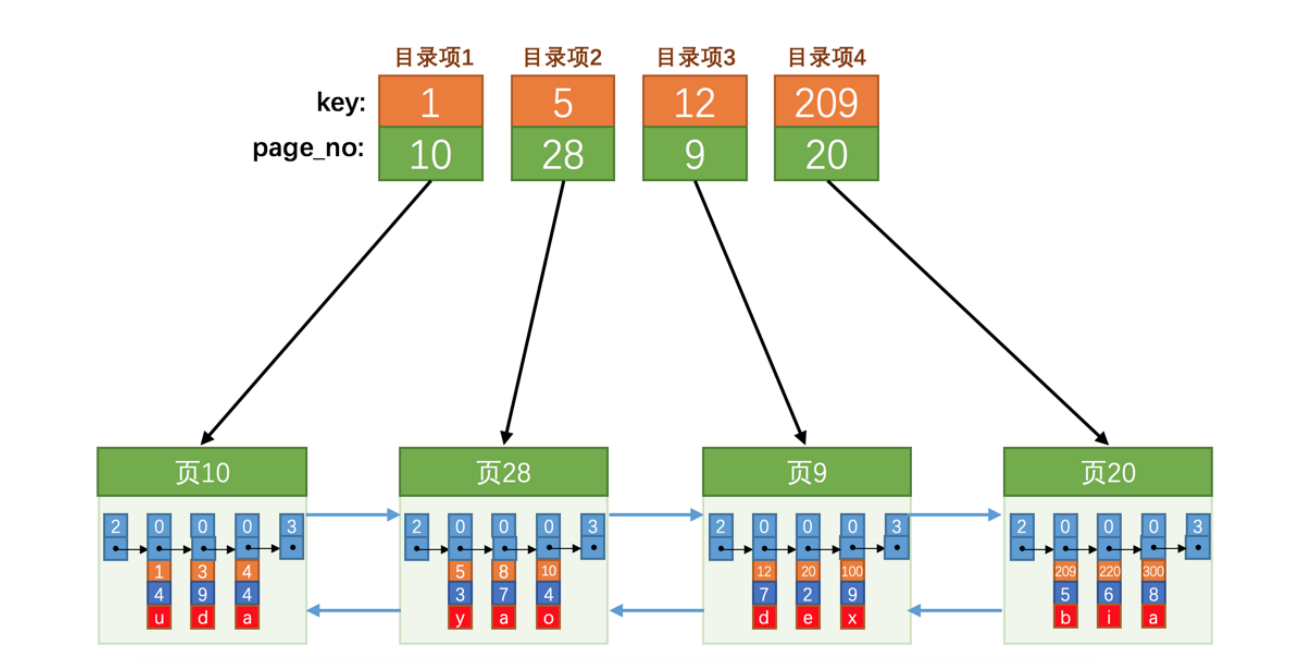
比方说我们想找主键值为20的记录,查找过程分两步:
- 从目录项中根据二分法确定主键值为20的记录在目录3(12<20<209),它对应的页是页9.
- 再在页内定位具体的记录.
我们上面假设的是目录项在物理上连续存储的,假如某个页面删除了,那么后面的目录项都需要向前移动,这种设计导致牵一发而动全身,所以设计者复用了之前存储用户记录的数据页来存储目录项,为了和用户记录做区分,使用record_type=1来记录,如下图所示: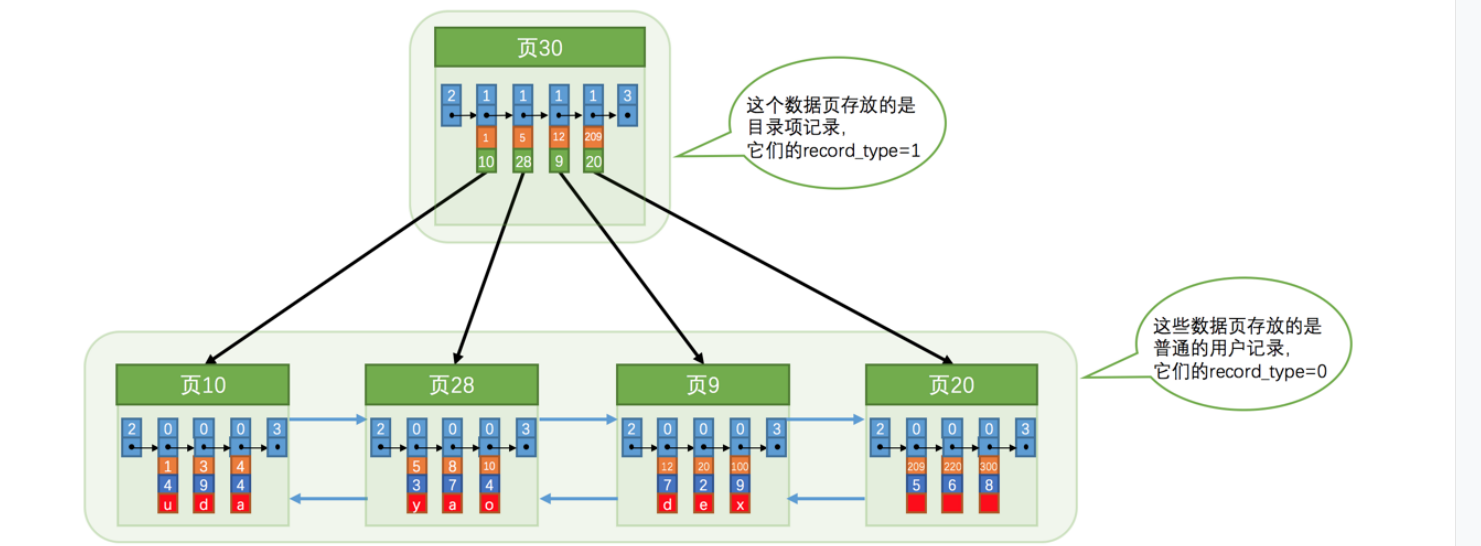
一个页的大小为16kb,如果一个页放不下所有的目录项,则需要多个页来存储,如下图所示: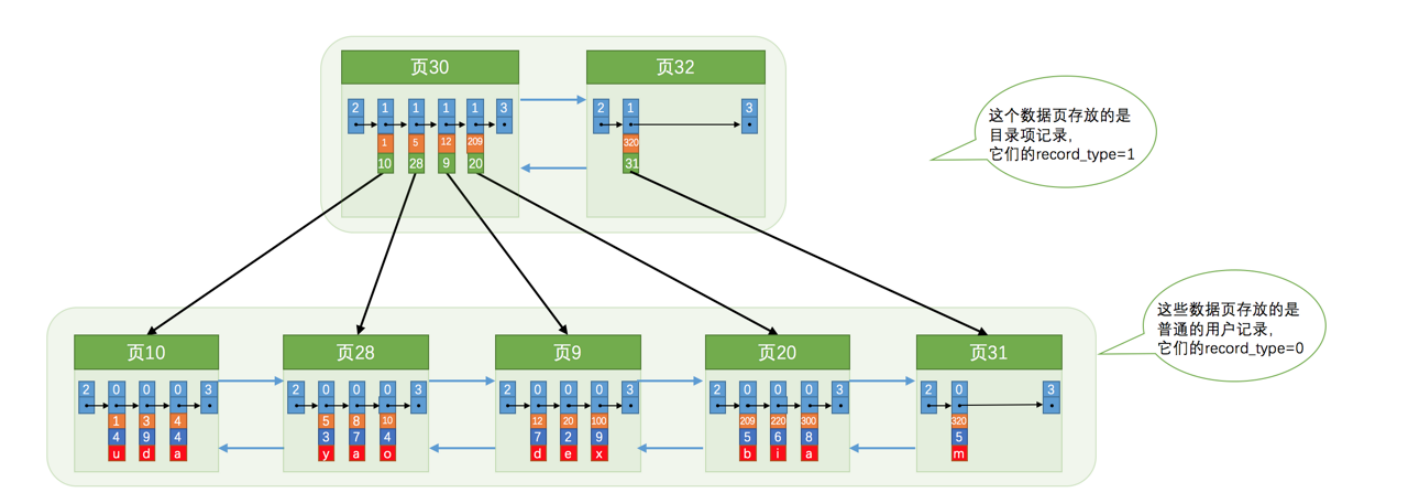
我们现在查询需要定位到目录项记录的页,那么我们怎么根据主键值快速定位到存储目录项记录的页呢,可以继续为目录项记录再生成一个高级记录页,如下图所示:
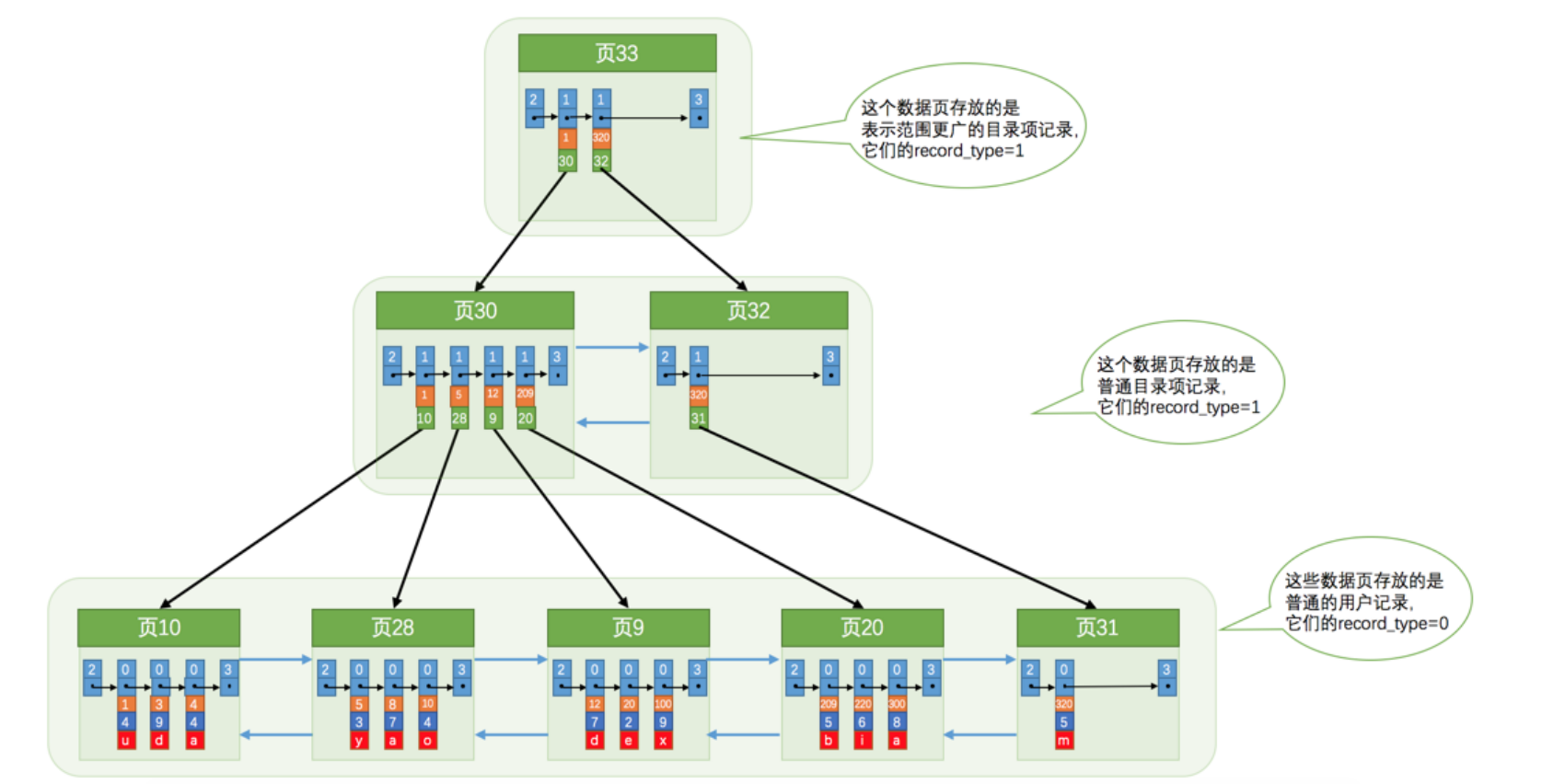
这其实就是一个B+树,实际的用户记录其实都存放在B+树的最底层节点上,也就是叶子节点,其余用来存储目录项的节点称为非叶子节点.
聚簇索引
- 使用记录主键值的大小进行记录和页的排序,包括三方面的含义:
- 页内的记录按照主键大小顺序排成一个单项链表
- 各个存放用户记录的页根据用户记录的主键大小顺序排成一个双向链表
- 存放目录项记录放在不同层次,在同一层次中的页也是根据页中目录项记录的主键大小排成一个双向链表
- B+树的叶子节点存储的是完整的用户记录(就是指这个记录存储了所以列的值)
聚簇索引并不需要我们使用index语句去创建,InnoDB存储引擎会自动的为我们创建聚簇索引,在InnoDB存储引擎中,聚簇索引就是数据的存储方式,也就是所谓的索引即数据,数据即索引.
二级索引
如果我们想用别的列作为搜索条件,我们可以再新建一个B+树,比如说我们使用C2列的大小作为数据页,页中记录的排序规则,再新建一个B+树,如下图所示: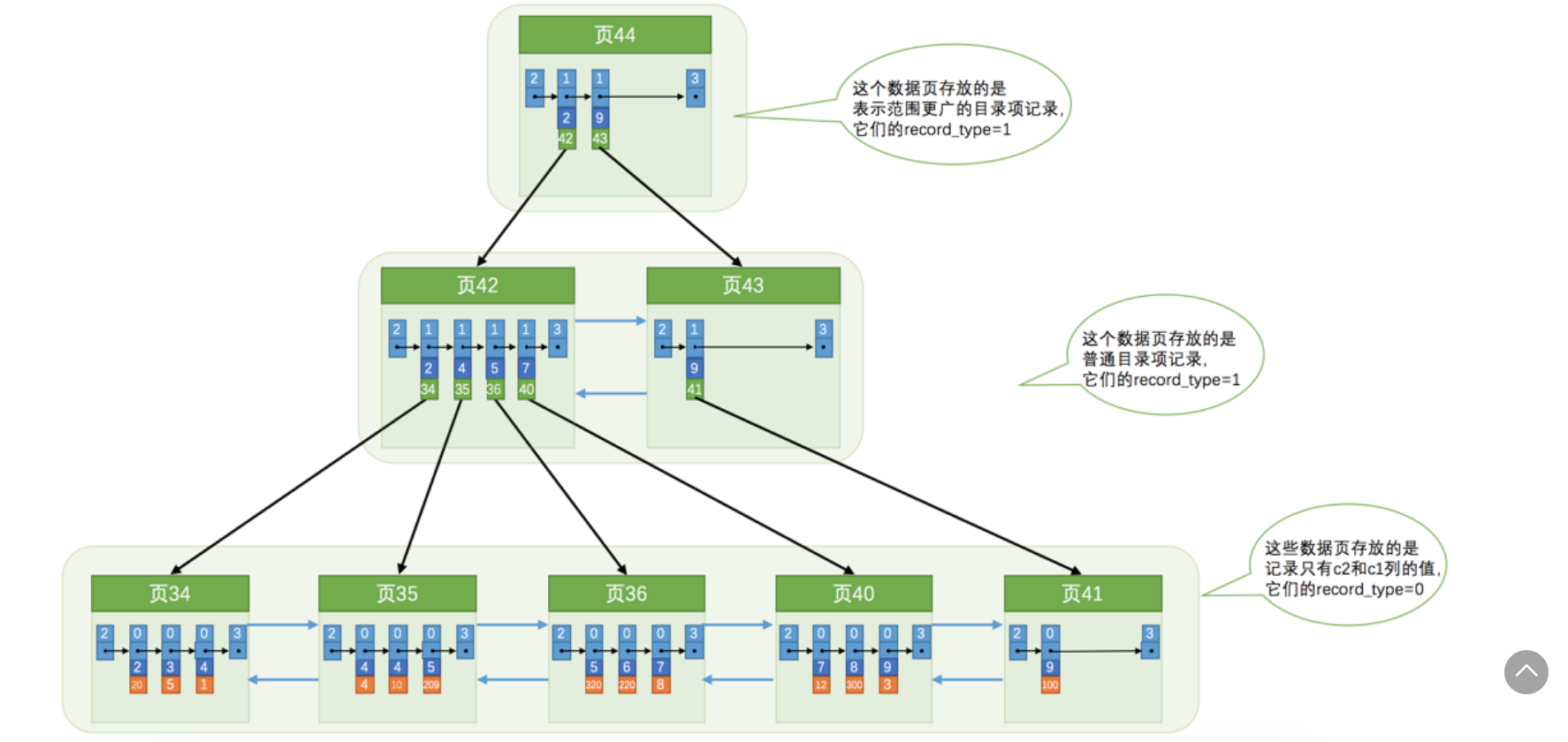
这个B+树与聚簇索引的不同之处:
使用记录c2列的大小进行记录和页的排序,包含3个方面的含义:
- 页内记录是按照c2列大小顺序排成一个单向链表
- 各个存放用户记录的页也是根据页中记录的c2列大小顺序排成一个双向链表
- 存放目录项记录的页分为不同的层次,在同一层次中的页也是根据页中目录项记录的c2大小顺序排成双向链表
B+树的叶子节点存储的不是完整的用户记录,而只是c2列+主键 这两个列的值
目录项记录中不再是主键+页号,而是c2+页号
现在根据c2(查找c2=4)查找过程如下:
- 确定目录项记录页(可以快速定位到目录项记录所在的页内42,因为2<4<9)
- 通过目录项记录页确定用户记录真实所在的页,可以确定在页34和35中
- 在页中定位到具体的记录,由于叶子节点只存储了c2和c1,所以我们必须再根据主键去聚簇索引中再查找一遍完整的用户记录,这个过程也称为回表
因为这种按照非主键建立的B+树需要一次回表操作才可以定位到完整的记录,所以这种B+树也被称为二级索引,或者辅助索引.
联合索引
我们也可以同时以多个列的大小作为排序规则,也就是同时为多个列建立索引,比如让B+树按照c2列和c3列的大小进行排序:
- 先把各个记录和页按照c2列进行排序
- 在记录的c2列相同的情况下,采用c3列进行排序.
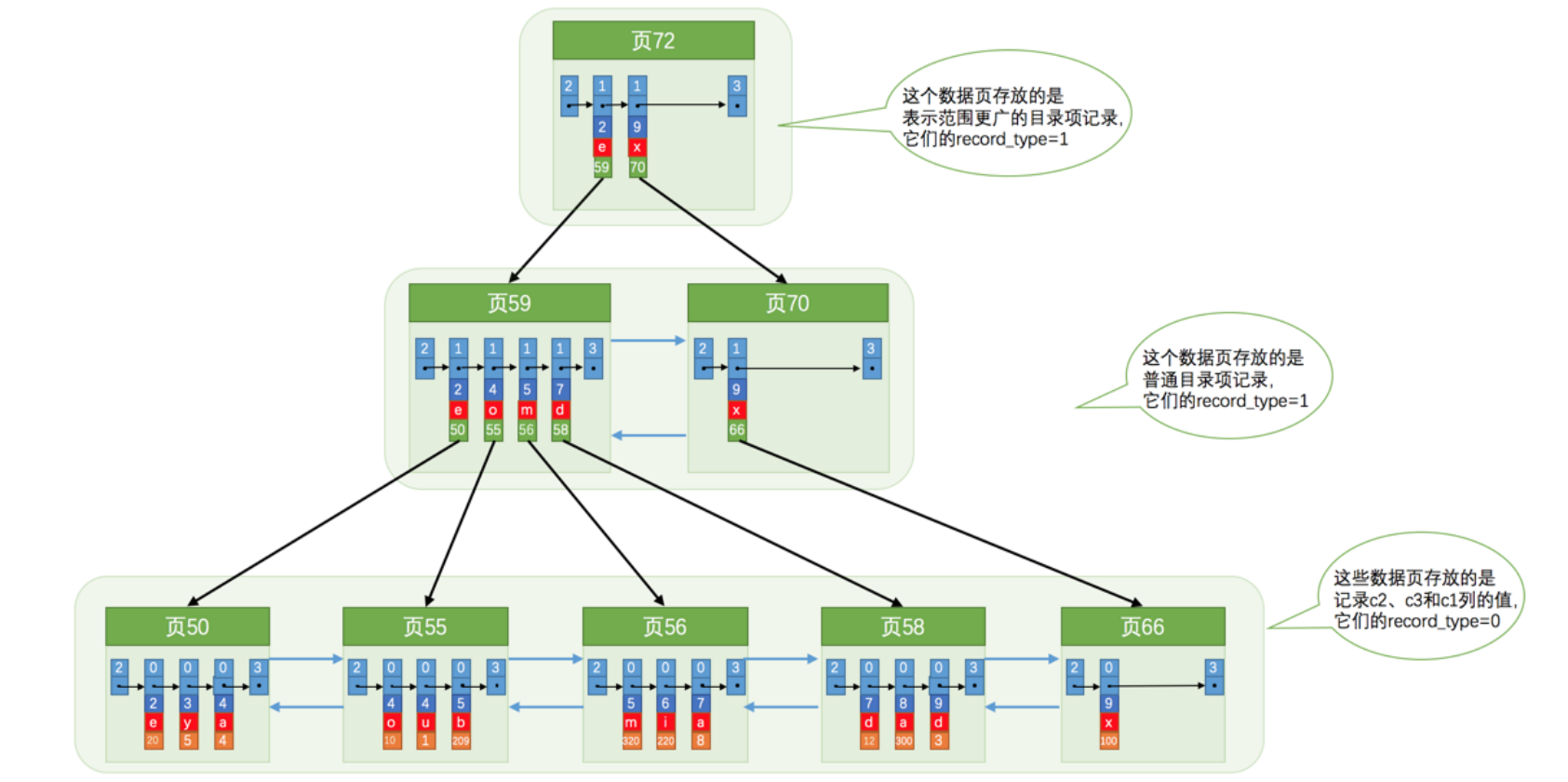
建立索引
InnoDB和MyISAM会自动为主键或者声明为UNIQUE的列去自动建立B+数索引,或者手动建立:
1 | |
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!